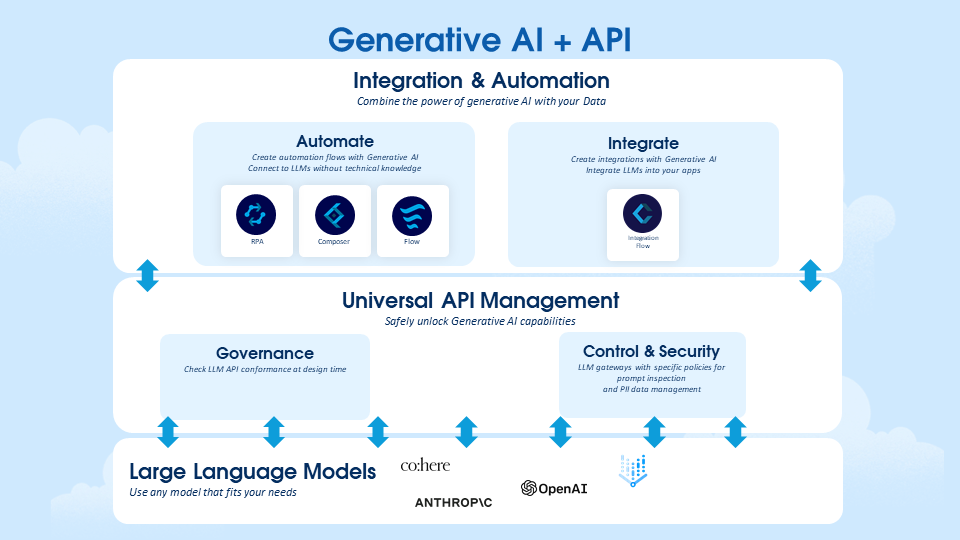
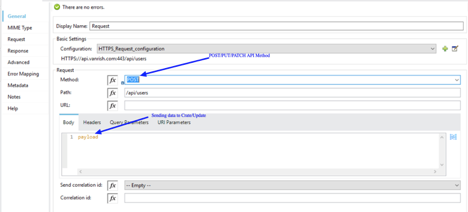
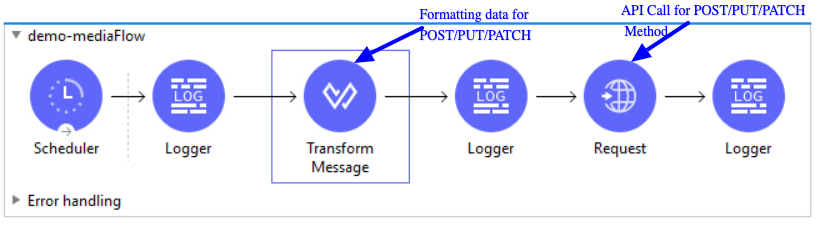
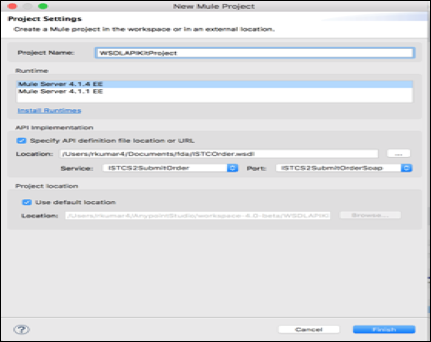
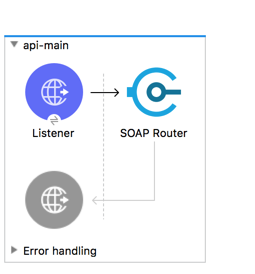
Modern-day APIs are the building block for integration and application for any organization. Every day organizations are using APIs to unlock new features and enable innovation. From banks, retail, and transportation to IoT, autonomous vehicles, and smart cities, APIs are a critical part of modern mobile, SaaS, and web applications and can be found in customer-facing, partner-facing, and internal applications.
Organizations are exposing sensitive data, such as Personally Identifiable Information (PII) through APIs, and because of this have increasingly become a target for attackers. Due to this organizations are concerned about their API security & compliance. API Security focuses on strategies and solutions to understand and mitigate the unique vulnerabilities and security risks of Application Programming Interfaces (APIs). According to the Open Web Application Security Project (OWASP) 2023, these API threats are categorized into 10 different categories
- Broken Object Level Authorization (BOLA) – Object-level authorization is an access control mechanism that is usually implemented at the code level to validate that a user can only access the objects that they should have permission to access.
Comparing the user ID of the current session (e.g. by extracting it from the JWT token) with the vulnerable ID parameter isn’t a sufficient solution to solve Broken Object Level Authorization (BOLA).
For example, any API providing a listing of all school revenue based on the school’s name of any county could be a security threat like this API endpoint: /county/{schoolName}/revenues.
Hacker simply manipulates {schoolName} in the above endpoint’s school name to get all revenue details for all schools.
To mitigate this risk Use the authorization mechanism to check if the logged-in user has access to perform the requested action on the record in every function that uses an input from the client to access a record in the database. - Broken Authentication – API authentication is very vulnerable and an easy target for attackers. Attackers can gain complete control of other users’ accounts in the system, read their personal data, and perform sensitive actions on their behalf.
API authentication flow and process need to be well protected and “Forgot password / reset password” should be treated the same way as authentication mechanisms. Make sure you know all possible flows to authentication to API (Mobile/Web/any link) and it gets well protected with authentication. - Broken Object Property Level Authorization – When authorizing a user to access an object using an API endpoint, It is very important to validate that the user has permission to access the specific or all object properties.
An API endpoint is considered as vulnerable if :
- The API endpoint exposes properties of an object that are considered sensitive and should not be read by the user.
- The API endpoint allows a user to change, add/or delete the value of a sensitive object’s property which the user should not be able to access.
When you are exposing any API endpoint, always make sure that the user has access to the object’s properties you expose and avoid using any generic methods like to_json() and to_string().
- Unrestricted Resource Consumption – Enabling any API request, requires resources such as network bandwidth, CPU, memory, and storage. These resources have limited bandwidth and money associated with these resources.
It is easy to exploit these resources by simple API calls or multiple concurrent requests. An API is vulnerable if at least one of the following limits is missing or set inappropriately.- Execution timeouts
- Maximum allowable memory
- Maximum number of file descriptors
- Maximum number of processes
- Maximum upload file size
- Number of operations to perform in a single API client request (e.g. GraphQL batching)
- Number of records per page to return in a single request-response
- Third-party service providers’ spending limit
- Broken Function Level Authorization – If any of the administrative API flows like delete, update, or create expose to unauthorized users it will be an easily vulnerable API endpoint. The best way to find broken function level authorization issues is to perform a deep analysis of the authorization mechanism while keeping in mind the user hierarchy, different roles or groups in the application, and asking the following questions:
- Can a regular user access the administrative endpoint?
- Can a user perform sensitive actions (e.g. creation, modification, or deletion) that they should not have access to by simply changing the HTTP method (e.g. from GET to DELETE)?
- Can a user from Group X access a function that should be exposed only to users from Group Y, by simply guessing the endpoint URL and parameters?
To mitigate this risk, the enforcement mechanism(s) must deny all access by default, requiring explicit grants to specific roles for access to every function.
- Unrestricted Access to Sensitive Business Flows — When you create an API endpoint some endpoints are more sensitive and critical than others. It is very important to understand which API endpoint and business flow you are exposing to the customer. Any restricted business flow exposed to clients can harm your business. In general, technical impact is not very severe but business impact might hurt your company’s credibility.
For example, if your company offers a discount for one customer 20% and another customer 30% through API, if the first customer knows this discount variation, it will impact the credibility of the company as well as revenue loss.
The mitigation planning should be done in two layers:
- Business – identify the business flows that might harm the business if they are excessively used.
- Engineering – choose the right protection mechanisms to mitigate the business risk.
- Server-Side Request Forgery – Server-Side Request Forgery (SSRF) vulnerability occurs when you are consuming remote APIs and resources without validating the remote endpoint or user-supplied URL. SSRF enables attackers to force the application to send formatted requests to an unknown destination even if protected by a firewall. Successful exploitation might lead to internal services enumeration (e.g. port scanning), information disclosure, bypassing firewalls, or other security mechanisms.
The SSRF risk cannot be eliminated but you can mitigate these risks by isolating the resource fetching mechanism in your network, accepting media types for a given functionality, disabling HTTP redirections, Validating and sanitizing all client-supplied input data, and Using a well-tested and maintained URL parser to avoid issues caused by URL parsing inconsistencies. - Security Misconfiguration — Security Misconfiguration vulnerability occurs when the latest patches are missing on the server or systems are outdated, Transport Layer Security (TLS) is missing, A Cross-Origin Resource Sharing (CORS) policy is missing, Error messages include stack traces or expose other sensitive information. Attackers often attempt to find unpatched flaws, common endpoints, services running with insecure default configurations, or unprotected files and directories to gain unauthorized access or knowledge of the system. These Security misconfigurations not only expose sensitive user data but also system details that can lead to full server compromise.
Security misconfiguration risk can be mitigated by a repeating hardening process leading to fast and easy deployment, ensuring all communication happens over an encrypted communication channel (TLS), and implementing a proper Cross-Origin Resource Sharing (CORS) policy. - Improper Inventory Management — It is important for organizations not only to have a good understanding and visibility of their own APIs and API endpoints but also how the APIs are storing or sharing data with external third parties. Multiple versions of APIs need to be properly managed, secure, patched and well-documented. Hackers usually get unauthorized access through old API versions or endpoints left running unpatched and using weaker security. requirements.
Improper Inventory Management security vulnerability can be mitigated by documenting all hosted APIs for all environments (Prod or Non-Prod), Generating documentation automatically by adopting open standards and avoiding using production data with non-production API deployments. - Unsafe Consumption of APIs — Unsafe Consumption of APIs vulnerability occurs when your developers tend to adopt weaker security standards, for instance, in regard to input validation, sanitization, URL redirections and not implementing timeouts for interactions with third-party services.
This vulnerability can be mitigated by implementing proper data validation, and schema validation. Ensuring all API interaction happens on secured communication channels like TLS. Maintain an allowlist of well-known locations integrated APIs may redirect yours to do not blindly follow redirects.
Rajnish Kumar, the CTO of Vanrish Technology, brings over 25 years of experience across various industries and technologies. He has been recognized with the “AI Advocate and MuleSoft Community Influencer Award” from the Salesforce/MuleSoft Community, showcasing his dedication to advancing technology. Rajnish is actively involved as a MuleSoft Mentor/Meetup leader, demonstrating his commitment to sharing knowledge and fostering growth in the tech community.
His passion for innovation shines through in his work, particularly in cutting-edge areas such as APIs, the Internet Of Things (IOT), Artificial Intelligence (AI) ecosystem, and Cybersecurity. Rajnish actively engages with audiences on platforms like Salesforce Dreamforce, World Tour, Podcasts, and other avenues, where he shares his insights and expertise to assist customers on their digital transformation journey.