The cybersecurity threat landscape has changed dramatically in the last couple of years. Every day new kinds of threats are coming and impacting the organization’s business. Infosec/Security teams have always had challenges with this new threat to find the root cause and mitigate these risks.
To mitigate and overcome these constant/real-time threats and risks, the security fraternity introduces Zero Trust Architecture (ZTA) Or Zero Trust Strategy (ZTS). ZTA is not a product or application, but it is a concept and practice to mitigate any risk for your organization.
What is ZTA/ZTS?
Zero Trust is an information security model that denies access to applications and data by default. Threat prevention is achieved by continuously validating for security configuration and posture before being granted or keeping access to applications and data across users and their associated devices. All entities are untrusted by default; least privilege access is enforced; and comprehensive security monitoring is implemented.
Here are the basic properties for ZTA/ZTS
Default deny
Access by policy only
For data, workloads, users, devices
Least privilege access
Security monitoring
Risk-based verification
How API implement ZTA/ZTS?
API Security focuses on strategies and solutions to understand and mitigate the unique vulnerabilities and security risks of Application Programming Interfaces (APIs). In API security we establish certain rules and processes to mitigate security risks. These rules and processes are around Zero trust architecture or strategy. Here are a few basic strategies in API security to implement ZTA.
All API communications are secured regardless of network location – This risk can be mitigated by ensuring all communication happens over an encrypted communication channel (TLS) and implementing a proper Cross-Origin Resource Sharing (CORS) policy. The endpoint for API needs to be exposed through the HTTPS protocol.
All API endpoints are authenticated regardless of their environments (Prod, QA, Dev) — By default, all APIs need to be authenticated and authorized using username/password, JSON Web Token (JWT), OAuth, OpenID Connect, or third-party services.
All API resources are protected and restricted to all users by default — Running multiple versions of an API requires additional management resources from the API provider and expands the attack surface. As per ZTA, make sure all API versions and their resources are restricted if it is not used by the user. Always validate and properly sanitize data received from integrated APIs before using it.
Access to API resources is determined by dynamic policy including the client identity, application/service, and the requesting asset – Any API requires resources such as network bandwidth, CPU, memory, and storage. It is easy to exploit these resources by simple API calls or multiple concurrent requests. According to Zero Trust Architect, all APIs must implement API policies like:
Client identity (ClientID/Client-Secret)
Execution timeouts (Rate limiting)
Maximum allowable memory
Maximum number of file descriptors
Maximum number of processes
Maximum upload file size
Implement or configure API monitoring posture and API Alert system — API monitoring helps identify and resolve performance issues as well as security vulnerability issues before they negatively impact users, which can impact user experience. The alert system notifies the operation team to mitigate risk quickly.
Continuous API security risk assessments – Continuous risk assessments help the Infosec/Security team identify any security risk gap. By conducting the security risk assessments, organizations establish a baseline of cybersecurity measurements, and such baselines could be referenced to or compared against future results to improve overall cyber posture and resiliency further and demonstrate progress. A Free Security assessments tool VAT is available to mitigate any security risk for your organization.
Organizations that have adopted the Zero Trust API model, see trust as fundamental to creating a positive, low-friction work culture for their clients and empowering the organization at all levels. Many of our Vanrish Technology clients, we worked with have many of the technologies in place that can be leveraged toward full Zero Trust architect model adoption.
Rajnish Kumar is CTO of Vanrish Technology with Over 25 years experience in different industries and technology. He is very passionate about innovation and latest technology like APIs, IOT (Internet Of Things), Artificial Intelligence (AI) ecosystem and Cybersecurity. He present his idea in different platforms and help customer to their digital transformation journey.
Modern-day APIs are the building block for integration and application for any organization. Every day organizations are using APIs to unlock new features and enable innovation. From banks, retail, and transportation to IoT, autonomous vehicles, and smart cities, APIs are a critical part of modern mobile, SaaS, and web applications and can be found in customer-facing, partner-facing, and internal applications.
Organizations are exposing sensitive data, such as Personally Identifiable Information (PII) through APIs, and because of this have increasingly become a target for attackers. Due to this organizations are concerned about their API security & compliance. API Security focuses on strategies and solutions to understand and mitigate the unique vulnerabilities and security risks of Application Programming Interfaces (APIs). According to the Open Web Application Security Project (OWASP) 2023, these API threats are categorized into 10 different categories
Broken Object Level Authorization (BOLA) – Object-level authorization is an access control mechanism that is usually implemented at the code level to validate that a user can only access the objects that they should have permission to access. Comparing the user ID of the current session (e.g. by extracting it from the JWT token) with the vulnerable ID parameter isn’t a sufficient solution to solve Broken Object Level Authorization (BOLA).
For example, any API providing a listing of all school revenue based on the school’s name of any county could be a security threat like this API endpoint: /county/{schoolName}/revenues. Hacker simply manipulates {schoolName} in the above endpoint’s school name to get all revenue details for all schools.
To mitigate this risk Use the authorization mechanism to check if the logged-in user has access to perform the requested action on the record in every function that uses an input from the client to access a record in the database.
Broken Authentication – API authentication is very vulnerable and an easy target for attackers. Attackers can gain complete control of other users’ accounts in the system, read their personal data, and perform sensitive actions on their behalf.
API authentication flow and process need to be well protected and “Forgot password / reset password” should be treated the same way as authentication mechanisms. Make sure you know all possible flows to authentication to API (Mobile/Web/any link) and it gets well protected with authentication.
Broken Object Property Level Authorization – When authorizing a user to access an object using an API endpoint, It is very important to validate that the user has permission to access the specific or all object properties. An API endpoint is considered as vulnerable if :
The API endpoint exposes properties of an object that are considered sensitive and should not be read by the user.
The API endpoint allows a user to change, add/or delete the value of a sensitive object’s property which the user should not be able to access.
When you are exposing any API endpoint, always make sure that the user has access to the object’s properties you expose and avoid using any generic methods like to_json() and to_string().
Unrestricted Resource Consumption – Enabling any API request, requires resources such as network bandwidth, CPU, memory, and storage. These resources have limited bandwidth and money associated with these resources.
It is easy to exploit these resources by simple API calls or multiple concurrent requests. An API is vulnerable if at least one of the following limits is missing or set inappropriately.
Execution timeouts
Maximum allowable memory
Maximum number of file descriptors
Maximum number of processes
Maximum upload file size
Number of operations to perform in a single API client request (e.g. GraphQL batching)
Number of records per page to return in a single request-response
Third-party service providers’ spending limit
Broken Function Level Authorization – If any of the administrative API flows like delete, update, or create expose to unauthorized users it will be an easily vulnerable API endpoint. The best way to find broken function level authorization issues is to perform a deep analysis of the authorization mechanism while keeping in mind the user hierarchy, different roles or groups in the application, and asking the following questions:
Can a regular user access the administrative endpoint?
Can a user perform sensitive actions (e.g. creation, modification, or deletion) that they should not have access to by simply changing the HTTP method (e.g. from GET to DELETE)?
Can a user from Group X access a function that should be exposed only to users from Group Y, by simply guessing the endpoint URL and parameters?
To mitigate this risk, the enforcement mechanism(s) must deny all access by default, requiring explicit grants to specific roles for access to every function.
Unrestricted Access to Sensitive Business Flows — When you create an API endpoint some endpoints are more sensitive and critical than others. It is very important to understand which API endpoint and business flow you are exposing to the customer. Any restricted business flow exposed to clients can harm your business. In general, technical impact is not very severe but business impact might hurt your company’s credibility.
For example, if your company offers a discount for one customer 20% and another customer 30% through API, if the first customer knows this discount variation, it will impact the credibility of the company as well as revenue loss. The mitigation planning should be done in two layers:
Business – identify the business flows that might harm the business if they are excessively used.
Engineering – choose the right protection mechanisms to mitigate the business risk.
Server-Side Request Forgery – Server-Side Request Forgery (SSRF) vulnerability occurs when you are consuming remote APIs and resources without validating the remote endpoint or user-supplied URL. SSRF enables attackers to force the application to send formatted requests to an unknown destination even if protected by a firewall. Successful exploitation might lead to internal services enumeration (e.g. port scanning), information disclosure, bypassing firewalls, or other security mechanisms.
The SSRF risk cannot be eliminated but you can mitigate these risks by isolating the resource fetching mechanism in your network, accepting media types for a given functionality, disabling HTTP redirections, Validating and sanitizing all client-supplied input data, and Using a well-tested and maintained URL parser to avoid issues caused by URL parsing inconsistencies.
Security Misconfiguration — Security Misconfiguration vulnerability occurs when the latest patches are missing on the server or systems are outdated, Transport Layer Security (TLS) is missing, A Cross-Origin Resource Sharing (CORS) policy is missing, Error messages include stack traces or expose other sensitive information. Attackers often attempt to find unpatched flaws, common endpoints, services running with insecure default configurations, or unprotected files and directories to gain unauthorized access or knowledge of the system. These Security misconfigurations not only expose sensitive user data but also system details that can lead to full server compromise.
Security misconfiguration risk can be mitigated by a repeating hardening process leading to fast and easy deployment, ensuring all communication happens over an encrypted communication channel (TLS), and implementing a proper Cross-Origin Resource Sharing (CORS) policy.
Improper Inventory Management — It is important for organizations not only to have a good understanding and visibility of their own APIs and API endpoints but also how the APIs are storing or sharing data with external third parties. Multiple versions of APIs need to be properly managed, secure, patched and well-documented. Hackers usually get unauthorized access through old API versions or endpoints left running unpatched and using weaker security. requirements. Improper Inventory Management security vulnerability can be mitigated by documenting all hosted APIs for all environments (Prod or Non-Prod), Generating documentation automatically by adopting open standards and avoiding using production data with non-production API deployments.
Unsafe Consumption of APIs — Unsafe Consumption of APIs vulnerability occurs when your developers tend to adopt weaker security standards, for instance, in regard to input validation, sanitization, URL redirections and not implementing timeouts for interactions with third-party services. This vulnerability can be mitigated by implementing proper data validation, and schema validation. Ensuring all API interaction happens on secured communication channels like TLS. Maintain an allowlist of well-known locations integrated APIs may redirect yours to do not blindly follow redirects.
Rajnish Kumar is CTO of Vanrish Technology with Over 25 years experience in different industries and technology. He is very passionate about innovation and latest technology like APIs, IOT (Internet Of Things), Artificial Intelligence (AI) ecosystem and Cybersecurity. He present his idea in different platforms and help customer to their digital transformation journey.
Generative AI is more like a child where you instruct child that don’t bounce basketball inside home, but child goes to bounce a soccer ball inside home. But this was not your expectation from child and then this action falls outside of your expectation. Now you add more parameters with your instruction then the child is more likely to get the response that you want.
Generative AI is the same, the more context and parameter we can give to generative AI the better our service replies, the better emails, the better product recommendations get from your Generative AI Models.
We’re all seeing some amazing demos of generative AI these days. Models trained on the whole internet are able to hold a conversation, explain their reasoning, and perform well at a broad variety of tasks.
You’ve probably started to play with Chat GPT, Google Bard, or Microsoft Bing. In your company folks are already experimenting with different ways of data to use it in their work.
These chat interfaces, as an initial proof of concept, are truly amazing. it’s already becoming clear, the ability to create significant business value and it will be dependent on your ability to INTEGRATE and MANAGE these systems and data.
But there are multiple barriers standing in the way of our ability to implement AI.
Fragmented data is hard to ingest into AI models.
Missing context leads to poor recommendations.
Lack of trust in how the LLMs will use your data.
Difficulty in acting on the recommendations because AI is completely detached from business processes.
And of course, overall security risks of accessing data across various systems.
Technology is moving fast, and the recent introduction of AI innovation is exciting, especially with the promise of increased productivity. If you look at a public source like Hugging Face, there are over 250k AI models compared to only 32 significant industry-produced machine learning models in 2022. If you pair these figures with the fact that the average enterprise has over 1000 applications, suddenly you have a lot of API integrations to account for.
Without addressing your system integration challenges, you risk deploying AI that results in generic data in, and generic insights out.
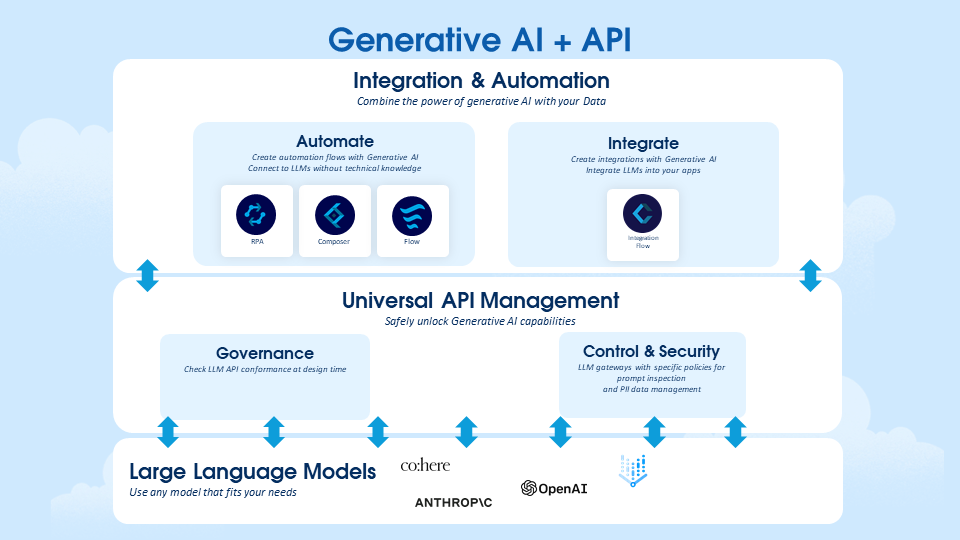
Generative AI and API ecosystem
Let’s find how API fits into this Large-language models (LLMs) or generative AI space.
You can start with an LLM of your choice, such as Salesforce CodeGen or OpenAI’s CoPilot.
A large language model (LLM) is a deep learning algorithm that can perform a variety of natural language processing (NLP) tasks.
As you know, big models incur big cost, and LLM’s are expensive.
So large language models are exposed as APIs to reduce cost. As we know, APIs are the easiest way to get data in and data out from these LLM. These LLM’s are open for anyone to use. These APIs are also pulling data from your existing system as well as legacy system. Now you are enabling APIs which is required for your business process and adding data context which is make sense to business use-case.
Next, you can establish control over the APIs for your LLM by applying governance and security policies using Universal API Management. In this way, you can assure that your organization is leveraging AI while remaining secure and conformant. Once your APIs are secured then you can add automation and integration flow with your APIs which communicate with your internal systems. Enabling AI data through API You can push and pull data from a variety of data sources, including 3rd party applications, to ensure that you are using the latest data with the latest technology and building a complete 360 view of your customer.
API Safely unlock generative AI capabilities through a layer of trust Use Universal API management (UPIM) to provide security and governance for AI driven systems. The integration and automation tools also ensure the customer 360 is all up to date with the latest data, making powerful customer experiences possible.
Rajnish Kumar is CTO of Vanrish Technology with Over 25 years experience in different industries and technology. He is very passionate about innovation and latest technology like APIs, IOT (Internet Of Things), Artificial Intelligence (AI) ecosystem and Cybersecurity. He present his idea in different platforms and help customer to their digital transformation journey.
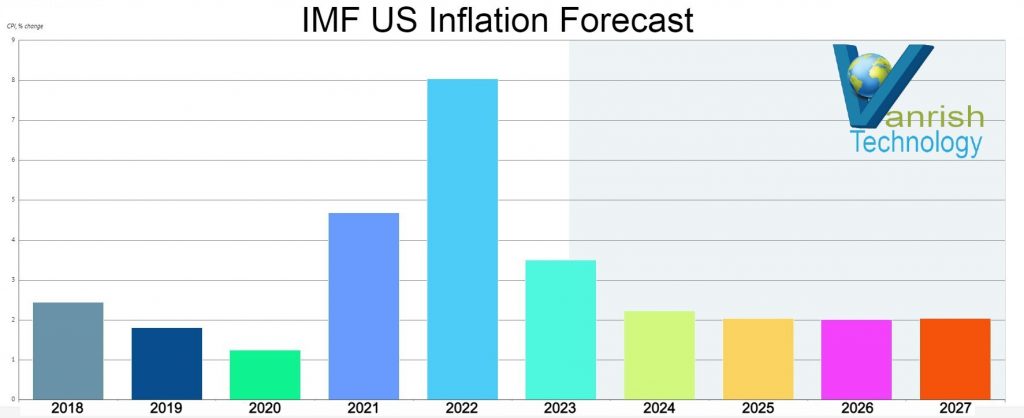
Global uncertainties continue to dominate headlines. Inflation is expected to reach the highest levels of ~3.5% in the US and Europe by the end of 2023. To ease inflation, Central Banks need to dampen demand, by making it expensive (for financial institutions, businesses and households) to borrow by increasing Federal Reserve interest rates . We are expecting a federal rate hike of 4.75% – 5.0% by the end of 2023. These are all data showing we are heading toward recession. The US labor market was robust last quarter but this quarter it is not very promising. Everyday we are hearing layoff news from different sectors.
IMF inflation forecast
These inflation and layoff news are impacting our tech market. Many companies have a growth challenge: They expect to get as much as 50 percent of their revenue from new businesses and products by 2026 but are not on a path that will take them there. Current economic conditions are forcing high-growth yet unprofitable tech startups to tighten their financial belts.
There are few realities, software companies are facing for their growth.
US-based Venture capitalists backed software startups slowed down – VC are very clear of high valuation and demanding that companies spend less, improve profit margin and high output. Unicorn creation also slowed in 2022 Q4. This is one of the lowest quarterly count since the first quarter of 2020.
Depressed company valuations – Private company valuations are cooling down. Over the last 4 quarters, we have seen public valuations compressing.
Software companies have three critical revenue streams.
License / Subscription Revenue – When the customer pays for the right to own and use a copy of the software/hardware product or subscribe/access software platform
software or hardware product – Customer pays for ongoing support or premium support.
Cloud based licensed software – Customer pays the software provider for specific deliverables such as software implementation or technical training.
In the current world all these 3 revenue streams are shrinking. Companies are using only essential services to run their business. This is directly impacting software revenue, which is leading these companies into low valuation.
Infrastructure Maintenance – SaaS companies are providing the software as a service. This means the customer does not have to purchase hardware to run the software—that cost is transferred to the SaaS provider. This is implying continuous software running coast. This cost is not going anywhere.So due to inflation this SaaS running cost increases tremendously.
Rajnish Kumar is CTO of Vanrish Technology with Over 25 years experience in different industries and technology. He is very passionate about innovation and latest technology like APIs, IOT (Internet Of Things), Artificial Intelligence (AI) ecosystem and Cybersecurity. He present his idea in different platforms and help customer to their digital transformation journey.
API is a key component of digital transformation. API is the interface of your legacy and SAAS data. The goal of APIs is to facilitate the transfer and enablement of data between your system and external users. APIs are typically available through public networks like the internet to communicate to external users and expose your data into the public domain.
Since your data is exposed into the public domain through APIs, It can lead to a data breach. APIs can be broken and expose sensitive personal as well as company data. An insecure API can be an easy target for hackers to gain access to your system and network. Rise of IOT devices and usage of APIs by these IOT devices, APIs are now more vulnerable.
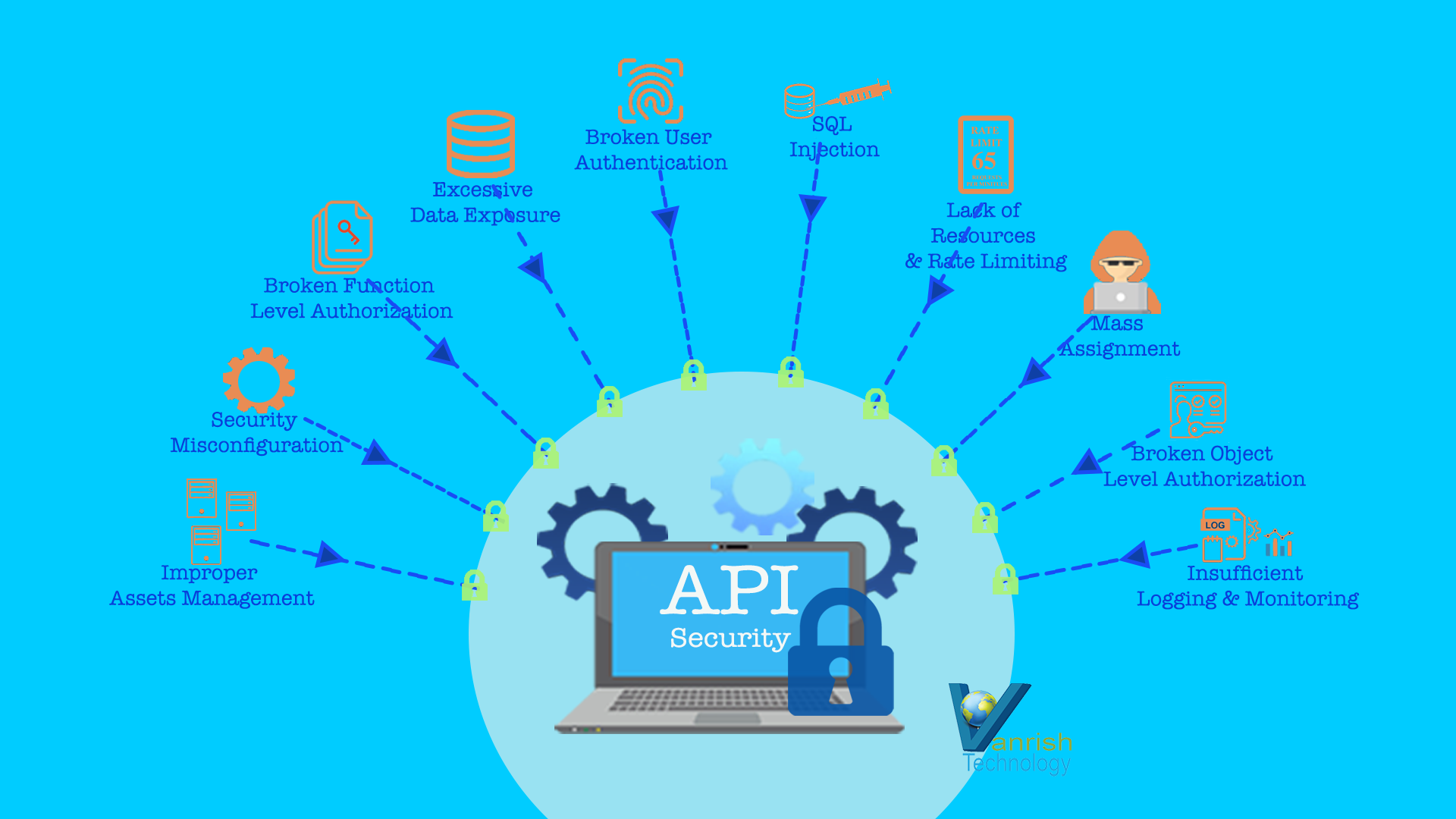
According to owasp, these are 10 main API vulnerabilities.
Broken Object Level Authorization – Expose endpoints that handle object identifiers, creating a wide attack surface Level Access Control issue.
Broken User Authentication – Authentication mechanisms are implemented incorrectly.
Excessive Data Exposure – Developers expose all object properties without considering their individual sensitivity
Lack of Resources & Rate Limiting – APIs do not impose any restrictions on the size or number of resources that can be requested by the client/user, lead to Denial of Service (DoS) attack on APIs
Broken Function Level Authorization– Complex access control policies with different hierarchies lead to authorization flaws.
Mass Assignment – Without proper properties filtering based on an allowlist, usually leads to Mass Assignment.
Security Misconfiguration – Misconfiguration or lack of Security configuration is commonly a result of insecure APIs
SQL Injection– SQL Injection occurs when untrusted data is sent to an interpreter as part of a command or query.
Improper Assets Management – APIs tend to expose more endpoints than traditional web applications lead to improper expose APIs.
Insufficient Logging & Monitoring – Insufficient logging and monitoring fail to find your vulnerability and broken integration.
How to mitigate API security risk?
API supports secure sockets layer (SSL), transport layer security (TLS), and Hypertext Transfer Protocol Secure (HTTPS) protocols, which provide security by encrypting data during the transfer process.
Apply Basic Auth minimum with API or if you want to more secure your API then enable 2 way authentication through OAuth framework .
Apply Authorization on each API resource to more control on API security through external Identity and access management provider (IAM).
Use encryption and signatures to all your API exposed personal and organizational sensitive data.
Apply API throttling through API manager to control number of user access per API (Rate Limiting).
Implement best practice of exception handling on your APIs to hide all your internal server and database information to mitigate SQL injection security risk.
Use Service Mesh to manage different layers of API management and control.
Audit your APIs and remove all unused API from your API catalog.
Add proper logging, Monitoring and Alerting on your APIs to keep track of your APIs activity.
Conclusion: APIs are a critical part of modern AI, mobile, SaaS, IOT and web applications. APIs Security should be the main focus on strategies and solutions to mitigate the unique vulnerabilities and security risks .
Rajnish Kumar is CTO of Vanrish Technology with Over 25 years experience in different industries and technology. He is very passionate about innovation and latest technology like APIs, IOT (Internet Of Things), Artificial Intelligence (AI) ecosystem and Cybersecurity. He present his idea in different platforms and help customer to their digital transformation journey.
The coronavirus (COVID-19) outbreak is one of the worst pandemic in recent history. This pandemic is affecting almost every person in the world. This pandemic is changing our living style, working style and also affecting our society.
This pandemic crisis raised a number of unique challenges among small and enterprise businesses. Organizations are navigating the business and facing unique operational challenges and delivering their product to their customers during the pandemic.
During this COVID-19 pandemic crisis here are few business challenges
Resource Management
Client Management
Digital/online transformation
Employee Remote work management
In this pandemic crisis API is playing a pivotal role to help their customers to migrate their business into digital through digital transformation solutions. API is playing a pivotal role to expedite digital transformation. API is also providing a platform and solution for crisis management during this pandemic.
Here is API solution for business
Make decisions — APIs are creating open platforms that expose critical COVID and organization data to enable organization proper management and tracking.These API enable data are helping to create dashboard and AI model. These dashboard and AI models help organizations to take decision or forecast their future strategy.
Respond and deliveries — Tracking and Management APIs are enabling organizations to respond quickly for any crisis and deliver their product on time.This helps any organization to expand their business and digitalize their legacy system & assets.
Return to work — APIs, templates and connectors are helping to unlock employee data. Organizations are integrating with ERP systems through APIs and unlocking their employee and resources data during pandemic. It is also facilitating/helping their employees to return their work during pandemic time either remote or onsite.
Simplify delivery — Enabling APIs, templates and micro-services are helping to simplify and improve their business process during pandemic.This is also helping to enable new innovation within organization and opening new business opportunity.
Covid 19 is also expediting digital transformation in healthcare. It is reshaping the way humans interact with technology in healthcare and Public Health Agencies or Federal Regulators. COVID-19 is also pushing healthcare organizations to embrace the idea of digital health and intelligent data integration as a tool. “Contact tracing” during pandemics is only possible through enablement of APIs. Federal and state governments are getting “contact tracing” patient data through API and using this data to trace down the source of pandemic.
API is also enabling pharmaceutical industries to deliver medicine fast and on time. It is also helping to manage and track medicine dose and availability.
Conclusion: Covid is disrupting whole industries and pushing companies to digital transform their process forever.
Rajnish Kumar is CTO of Vanrish Technology with Over 25 years experience in different industries and technology. He is very passionate about innovation and latest technology like APIs, IOT (Internet Of Things), Artificial Intelligence (AI) ecosystem and Cybersecurity. He present his idea in different platforms and help customer to their digital transformation journey.
Keep the application synchronous if possible. Synchronous flows avoid serialization/deserialization of messages sent through VM queues, do not cause context switches, and do not cause contention when messages move across thread pools.
Store as little as possible in variables. The vars are serialized and deserialized every time a message crosses an endpoint, even if it is a VM endpoint. This will impact performance overhead in direct proportion to the size of variables and the number of endpoints.
Use Dataweave Java payloads whenever possible. The usage of a canonical data model is recommended for projects that deal with data (mapping, transformation etc.). It is also recommended to create them in Java objects as dataweave whenever possible, as this provides the fastest format to access fields and change information and to convert to other formats.
Encourage dataweave languages. For better performance, use Dataweave for simple data extraction from messages, and Java components with dataweave for everything else.
Use flow references instead of VM endpoints. To communicate between flows internally within an application, use flow references instead of VM endpoints. The VM connector, even though it is an in-memory protocol, emulates transport semantics that serialize and deserialize parts of your messages, most notably the vars. This makes it slower than a flow reference, which just injects messages into the referenced flow with no intermediate steps. Please note that in some cases the usage of VM endpoints is preferred (see the chapter on reliability patterns). For example, a Mule cluster can load balance applications that use VM endpoints by deferring execution to another, available node in the cluster.
Cache aggressively. Take advantage of Mule’s caching scope when making requests to external resources like Web services or databases. Also consider caching reusable assets such as security tokens or ephemeral API keys and cookies. Mule’s Notification subsystem can additionally be used to “warm up” a cache when Mule starts. For example, consider doing this for situations where an initial cache miss is not acceptable.
Configure message processors and endpoints at the global level. Some connectors allow you to configure some parameters at both the global and the endpoint/message processor level. We recommend placing the configuration at a global level to avoid repeated initialization of resources.
Avoid creating a large volume of business events. Business events incur performance overhead in Mule and in platform when platform’s internal event buffer overflows. Thus, avoid using either default flow level business events or a large volume of custom business events in a high message volume project.
Consider using message compression. For communicating between Mule applications over the network consider using Mule’s compression processors to compress/decompress the message payloads before they hit the wire if their sizes are large.
Consider using VM queues instead of an external message broker. VM queues are fast and have some guaranteed delivery semantics in a cluster. Consider using these instead of going out to an external messaging broker for inter-application Mule communication.
Use the async scope when appropriate. If a flow is performing processing on a message that is neither modifying the message nor changing how it is routed, then it could be wrapped in an async block. This will cause the processing to occur in a different thread and will avoid adding unnecessary overhead to processing the message.
Use connection pooling for connectors because the performance cost of establishing a connection to another data source, such as a database, is relatively high.
Optimize your logging within your mule flows. Too much logging will slow down your process and too less logging will hard to debug.
Encryption and decryption of data is very costly. Whenever your Mule application really needs then apply encryption/decryption on your data.
Rajnish Kumar is CTO of Vanrish Technology with Over 25 years experience in different industries and technology. He is very passionate about innovation and latest technology like APIs, IOT (Internet Of Things), Artificial Intelligence (AI) ecosystem and Cybersecurity. He present his idea in different platforms and help customer to their digital transformation journey.
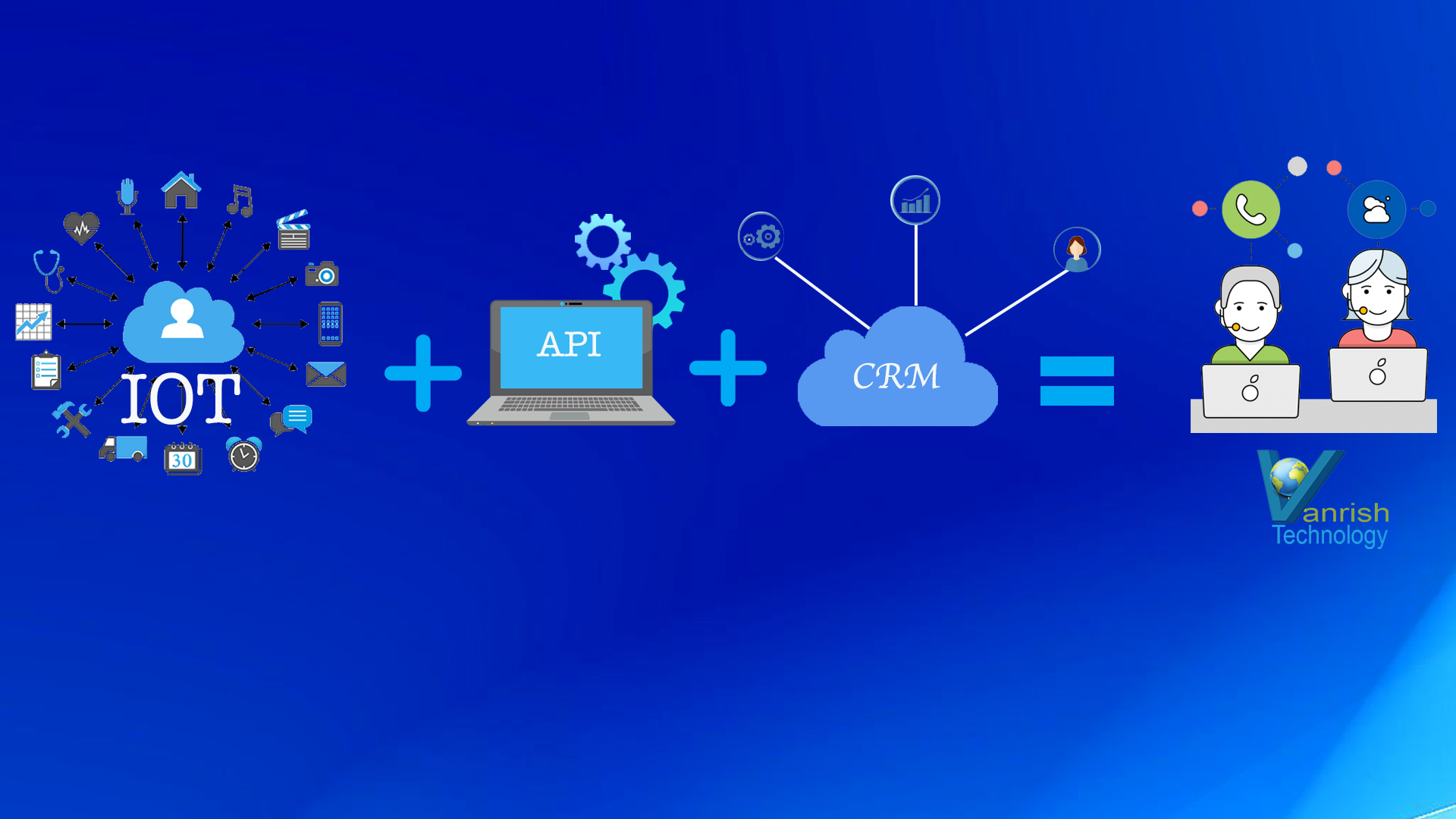
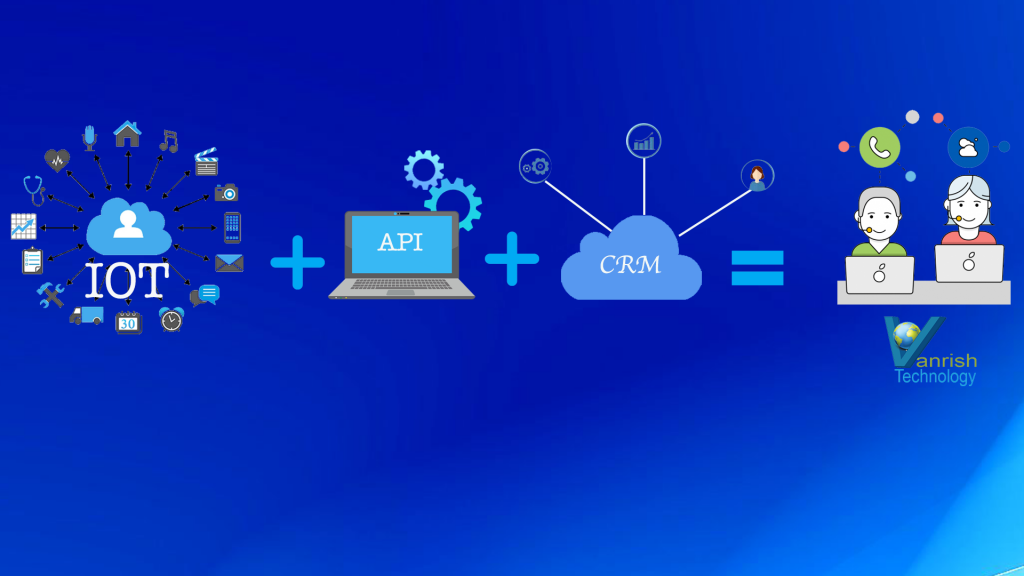
APIs integration helping IOT and CRM to enable better customer experience
IOT (Internet of things) is revolutionizing our lives. As per Gartner report by 2025 IOT market will expand a 58-billion-dollar opportunity. It is affecting all parts of our life. In our pandemic era we found more use of IOT device to maintain social distancing.
IOT is also one of the main disruptive technologies in our
businesses. It is affecting all business domain including healthcare, retail, automotive,
security.
There are wide range of IOT benefits in business.
Enhanced productivity
Better customer experience
Cost-effectiveness
CRM system is keeping all your customer relationship like
data, notes, metrics and more – in one place. CRM is helping small business to
take off all burden from the IT management team by automating the business
process. It is also helping employee to keep the focus on the critical business
areas.
API is helping to integrate these two unrelated systems.
APIs are enabling this system to optimize process and streamline whole business
process. API is the main communication channel to build robust process and
keeping real time update to these systems. APIs are allowing to build context-based
application with IOT and CRM to interact with the physical world.
Now here are few areas where IOT is helping CRM system with help of APIs to optimize business process.
Optimize customer service – Before your customer finds any error in your service/product you proactively acting on error and fixing those error. This will help to build relationship with customer.
Increase sales – With help of IOT and CRM system you are finding untouched opportunity and using those opportunity to increase your sale.
Personalize customer experience – You are analyzing data provided by IOT and CRM system and building user based predictive model to enable personalize experience to user.
Customer retention – CRM provide customer data and relationship. IOT data providing customer behavior. This will help any business to personalize and target marketing for their customer.
Omnichannel instore experience – IOT and CRM is helping business to enable 360 omnichannel customer experience. This process will help and suggest the products which the customer might purchase.
APIs integration with
IOT and CRM helping business to enable higher degree of personalization, target
marketing, optimize price model, higher revenue and enhance customer
satisfaction.
Rajnish Kumar is CTO of Vanrish Technology with Over 25 years experience in different industries and technology. He is very passionate about innovation and latest technology like APIs, IOT (Internet Of Things), Artificial Intelligence (AI) ecosystem and Cybersecurity. He present his idea in different platforms and help customer to their digital transformation journey.
Mule 4 introduced APIKit for soap webservice. It is very similar to APIKit for Rest. In SOAP APIKit, it accepts WSDL file instead of RAML file. APIKit for SOAP generates work flow from remote WSDL file or downloaded WSDL file in your system.
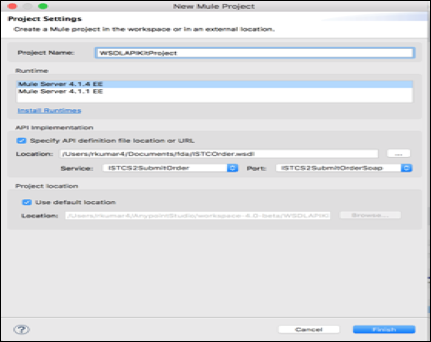
To create SOAP APIKit project, First create Mulesoft project with these steps in Anypoint studio.
Under File Menu -> select New -> Mule Project
Mule 4 Project Settings
In above pic WSDL file gets selected from local folder to create Mule Project.
Once you click finish, it generates default APIKit flow based on WSDL file.
In this Mulesoft SOAP APIKit example project, application is consuming SOAP webservice and exposing WSDL and enabling SOAP webservice.
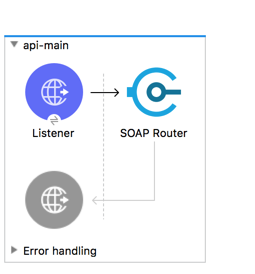
Mule 4 API Kit for Soap Router
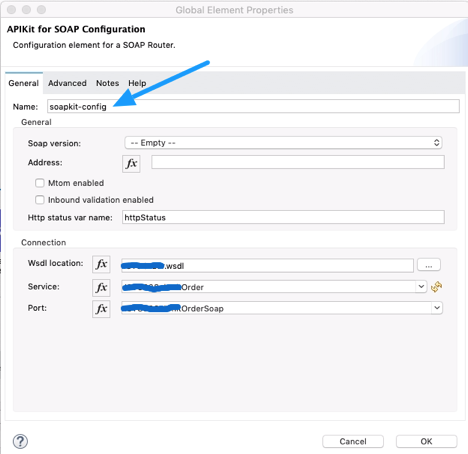
In SOAP Router APIKit, APIKit SOAP Configuration is defined WSDL location, Services and Port from WSDL file.
API Kit SOAP configuration
In above configuration, “soapkit-config” SOAP Router look up for requested method. Based on requested method it reroutes request from api-main flow to method flow. In this example, requested method is “ExecuteTransaction” from existing wsdl, so method flow name is
<flow name=“ExecuteTransaction:\soapkit-config”>
In this example we are consuming same WSDL but end point is different.
To call same WSDL we have to format our request based on WSDL file. In dataweave, create request based on WSDL and sending request through HTTP connector.
Here is dataweave transformation to generate request for existing WSDL file
Rajnish Kumar is CTO of Vanrish Technology with Over 25 years experience in different industries and technology. He is very passionate about innovation and latest technology like APIs, IOT (Internet Of Things), Artificial Intelligence (AI) ecosystem and Cybersecurity. He present his idea in different platforms and help customer to their digital transformation journey.
Much awaited Mulesoft 4 was officially announced in Mulesoft
Connect 2018 in San Jose. When Mulesoft was born, it was really to create
software that helps to interact systems or source of information quickly within
or outside company. So the speed is an incredibly important thing over the
years to develop and interact within systems. Need of speed for application and
development hasn’t change drastically over the years but needs and requirement
of customer’s application have changed. The integration landscape has also
magnified. There are hundreds of new systems and sources of information to
connect to, with more and more integration requirements. This integration
landscape gets very messy and very quickly.
Mule 4 provides
a simplified language, simplified runtime engine and ultimately reduces
management complexity. It helps
customers, developers to deliver application faster. Mule4 is really radically
simplified development. It is providing new tool to simplify your development,
deployment and management of your integration/API. It is also providing a
platform to reuse Mule component without affecting existing application for
faster development. Mule 4 is evolution of Mule3. You will not seem lost in
Mule 4, if you are coming from Mule3. But Mule 4 implements fewer concepts and
steps to simplify whole development/integration process. Mule 4 has now java
skill is optional. In this release Mulesoft is improving tool and making error
reporting more robust and platform independent.
Now let’s go one by one with all these new Mule4 features.
1. Simplified
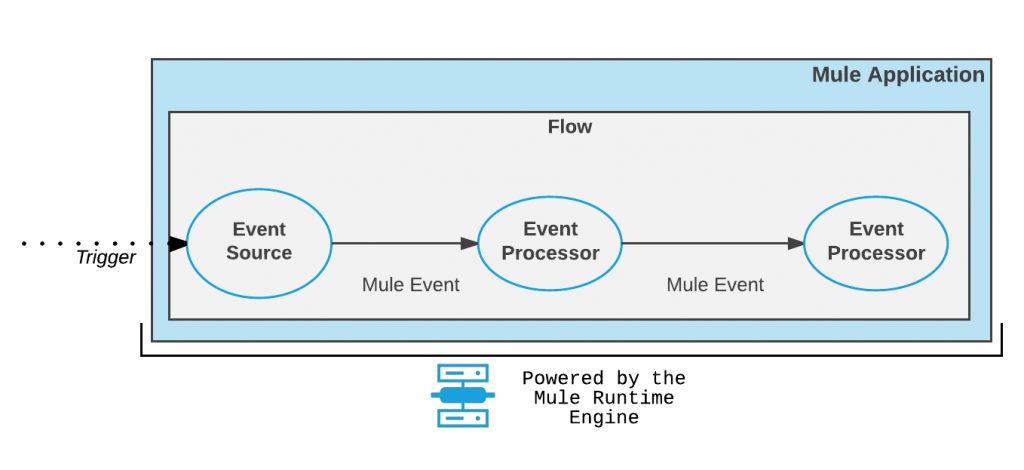
Event Processing and Messaging — Mule event is
immutable, so every change to an instance of a Mule event results in the
creation of a new instance.It contains the core
information processed by the runtime. It travels through components inside your
Mule app following the configured application logic. A Mule event is generated when a trigger (such as an
HTTP request or a change to a database or file) reaches the Event source of a
flow. This trigger could be an external event triggered by a resource that
might be external to the Mule app.
Mule 4 Event flow
2. New
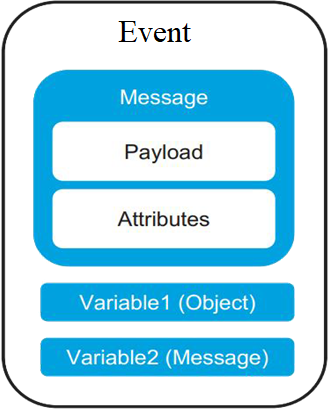
Event and Message structure — Mule 4 includes a
simplified Mule message model in which each Mule event has a message and
variables associated with it. A Mule message is
composed of a payload and its attributes (metadata, such as file size).
Variables hold arbitrary user information such as operation results, auxiliary
values, and so on.
Mule 4 message
Mules 4 do not have Inbound, Outbound and Attachment
properties like Mule 3. In mule 4 all information
are saved in variables and attributes. Attributes in Mule 4 replace inbound properties. Attributes
can be easily accessed through expressions.
These
are advantages to use Attributes in
Mule 4.
They are strongly typed, so you can easily see
what data is available.
They can easily be stored in variables that you
can access throughout your flow
Example :
#[attributes.uriParams.jobnumber]
Outbound properties— Mule 4 has no concept for outbound properties like in Mule 3. So you can set status code response or header information in Mule 4 through Dataweave expression without introducing any side effects in the main flow.
Session Properties–In Mule 4 Session properties are no longer exist. Data store in variables are passes along with different flow.
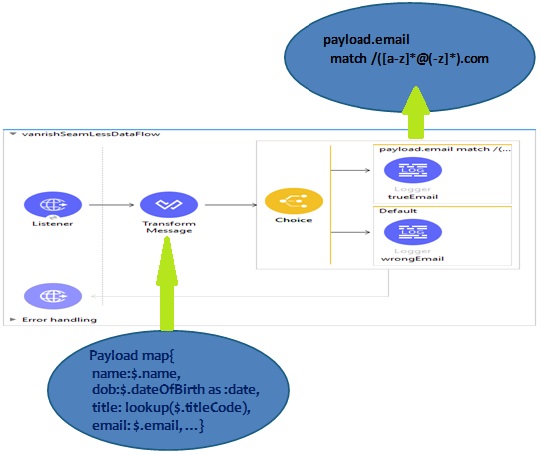
3. Seamless data access & streaming – Mule 4 has fewer concepts and steps. Now every steps and task of java language knowledge is optional.Mule 4 is not only leveraging DataWeave as a transformation language, but expression language as well. For example in Mule 3 XML/CSV data need to be converted into java object to parse or reroute them. Mule 4 gives the ability to parse or reroute through Dataweave expression without converting into java. These steps simplify your implementation without using java.
Mule 4 Data Access
4. Dataweave 2.0 — Mule 4 introduces DataWeave as the default
expression language replacing Mule Expression Language (MEL) with a scripting
and transformation engine. It is combined with the built-in streaming
capabilities; this change simplifies many common tasks. Mule 4
simplifies data iteration. DataWeave knows how to iterate a json array. You
don’t even need to specify it is json. No need to use <json:json-to-object-transformer /> to convert data into java object.
Mule 4 vs Mule 3 flow comparison
Here are few points about Dataweave 2.0
Simpler syntax to learn
Human readable descriptions of all data types
Applies complex routing/filter rules.
Easy access to payload data without the need for
transformation.
Performs any kind of data transformation,
normalization, grouping, joins, pivoting and filtering.
5. Repeatable
Streaming – Mule 4 introduces
repeatable streams as its default framework for handling streams. To understand
the changes introduced in Mule 4, it is necessary to understand how Mule3 data
streams are consumed
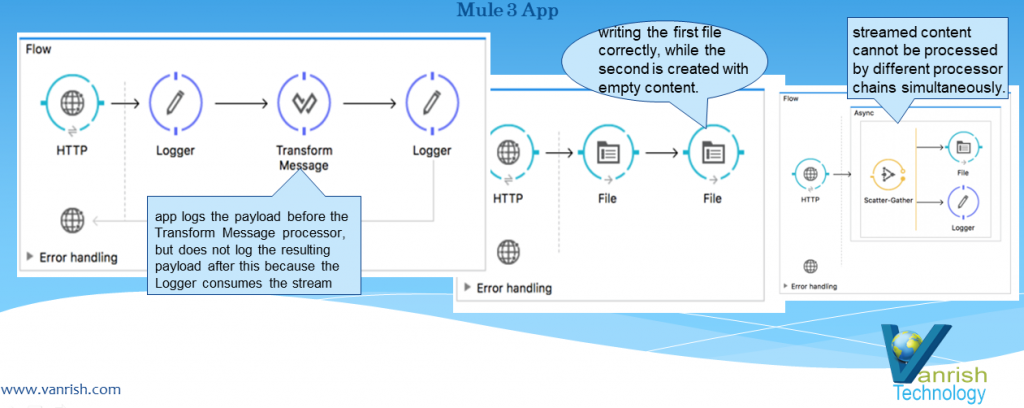
Mule 3 data streaming examples
In above three different Mule 3 flows, once stream data is
consumed by one node it is empty stream for 2nd node. So in the above
first example, in order to log the stream payload , the logger has to consume
the entire stream of data from HTTP connector. This means that the full content
will be loaded into memory. So if the content is too big and you’re loading
into memory, there is a good chance the application might run out of memory.
So Mule 4 repeatable streams enable you to
Read a stream more than once
Have concurrent access to the stream.
Random Access
Streams of bytes or streams of objects
As a component consumes the stream, Mule saves its content
into a temporary buffer. The runtime then feeds the component from the
temporary buffer, ensuring that each component receives the full stream,
regardless of how much of the stream was already consumed by any prior
component
Here are few points, how repeatable streams works in Mule 4
Payload
is read into memory as it is consumed
If
payload stream buffer size is > 512K (default) then it will be persisted to
disk.
Payload
stream buffer size can be increased or decreased by configuration to optimize
performance
Any
stream can be read at any random position, by any random thread concurrently
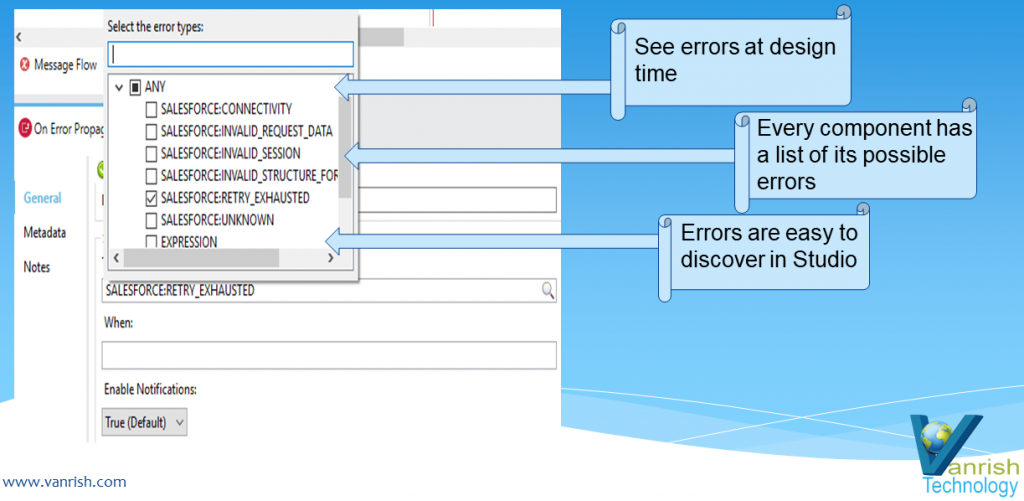
6. Error Handling — In Mule 4 error handling has been changed
significantly. Now In mule 4 you can discover errors at design time with visual
interface. You no need to deal with java exception directly and it is easy to
discover error while you are building flow. Every flow listed all possible
exception which potential arises during execution.
Mule 4 Error Handling
Now errors that occur
in Mule fall into two categories
Messaging errors
System errors
Messaging errors — Mule throws a messaging error (a Mule error) whenever a problem occurs within a flow. To handle Mule
errors, you can set up On Error components inside the scope-like Error Handler
component. By default, any unhandled errors are logged and propagated.
System errors — Mule throws a system error when an exception occurs
at the system level . If no Mule Event is involved, the errors are handled by a
system error handler.
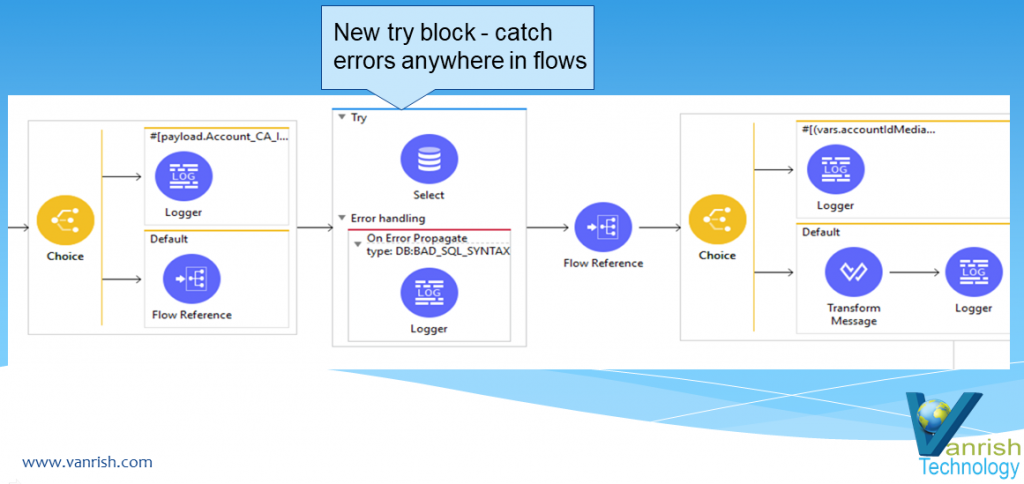
Try catch Scope — Mule 4 introduces a new try scope that you can use within a flow to do error handling of just inner components/connectors. This try scope also supports transactions and in this way it is replacing Old Mule 3 transaction scope.
Mule 4 A new try catch block
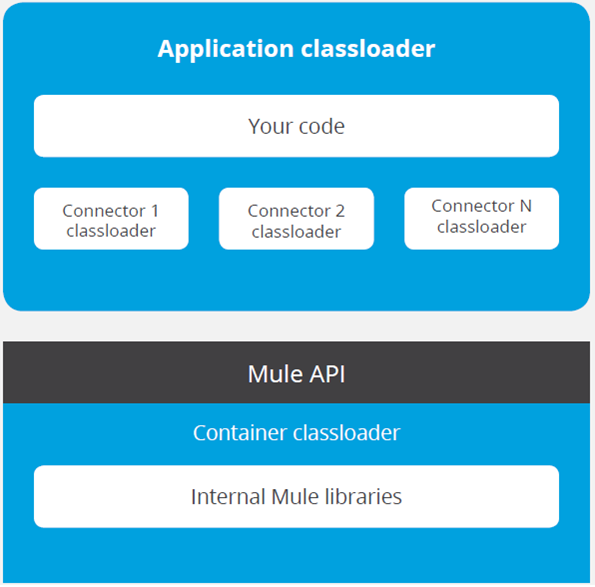
7. Class Loader Isolation — Class loader separates application completely from
Mule runtime and connector runtime. So, library file changes (jar version) do
not affect your application. This also
gives flexibility to your application to run any Spring version without worry
about Mulesoft spring version. Connectors are distributed outside the runtime
as well, making it possible to get connector enhancements and fixes without
having to upgrade the runtime or vice versa
In above pic showing that every component in any application have their own class loader and running independently on own class loader.
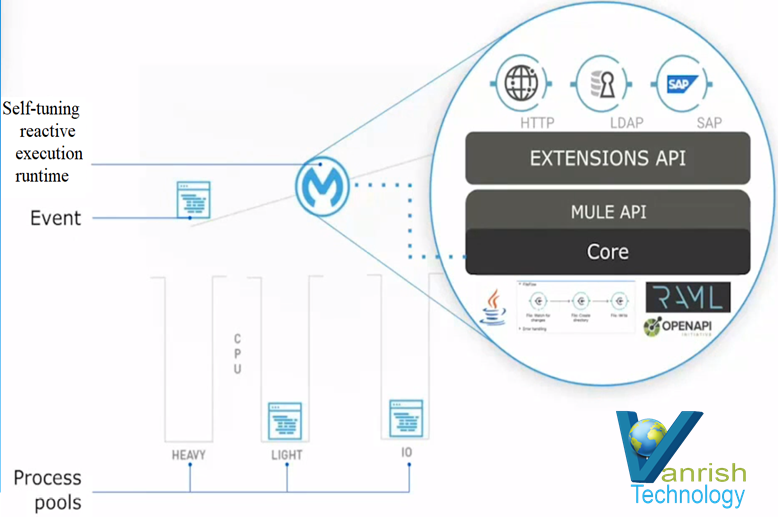
8. Runtime Engine — Mule 4 engine is new reactive and non-blocking engine. In Mule 4 non-blocking flow always on, so no processing strategy in flow. One best feature of Mule 4 engine is, It is self-tuning runtime engine. So what does this mean? If Mule 4 engine is processing your applications on 3 different thread pools, So runtime knows which application should be executed by each thread pool. So operation put in corresponding thread pool based on high intensive CPU processing or light intensive CPU processing or I/O operation. Then 3 pools are dynamic resizing automatically to execute application through self-tuning.
Mule 4 : Self tuning run time engine
So now self-tuning creates custom thread pools based on specific tasks. Mule 4 engine makes it possible to achieve optimal performance without having to do manual tuning steps.
Conclusion
Overall Mule 4 is
trying to make application development easy, fast and robust. There are more features
included in Mule 4 which I will try to cover in my next blog. I will also try
to cover more in depth info in above topic of Mule 4. Please keep tuning for my
next blog.
Rajnish Kumar is CTO of Vanrish Technology with Over 25 years experience in different industries and technology. He is very passionate about innovation and latest technology like APIs, IOT (Internet Of Things), Artificial Intelligence (AI) ecosystem and Cybersecurity. He present his idea in different platforms and help customer to their digital transformation journey.