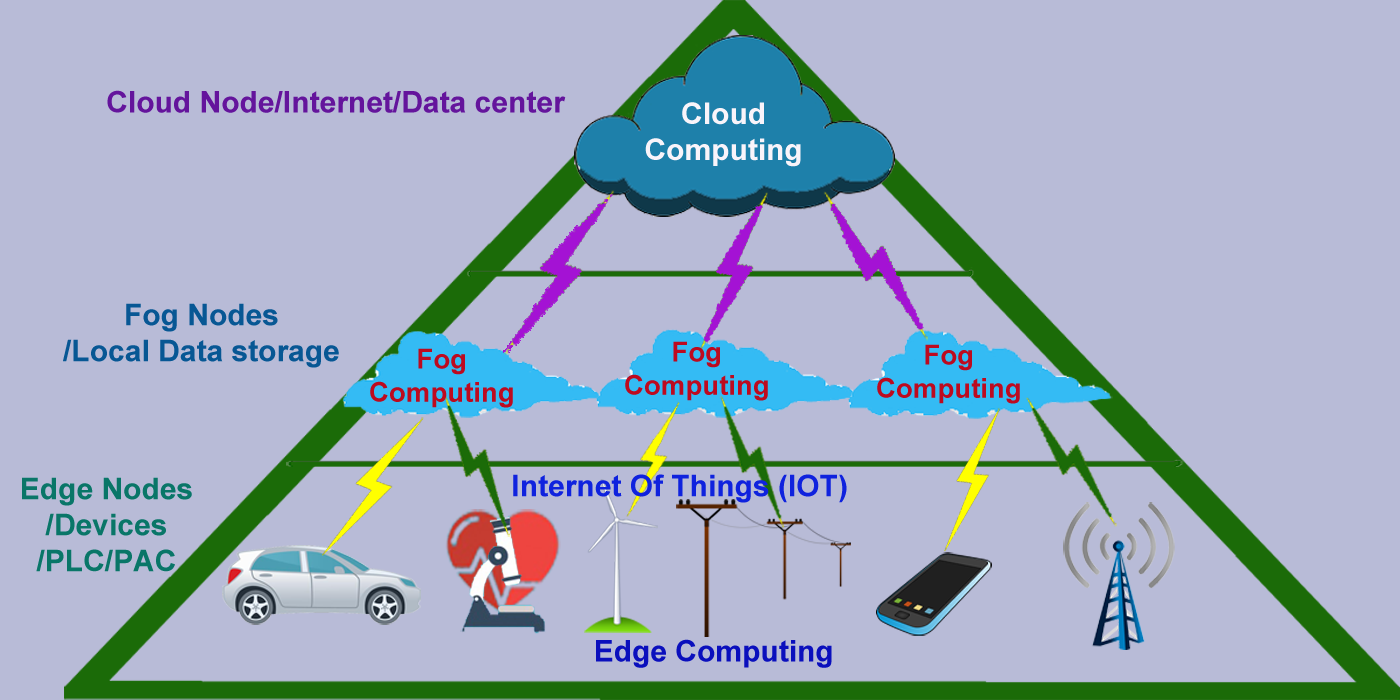
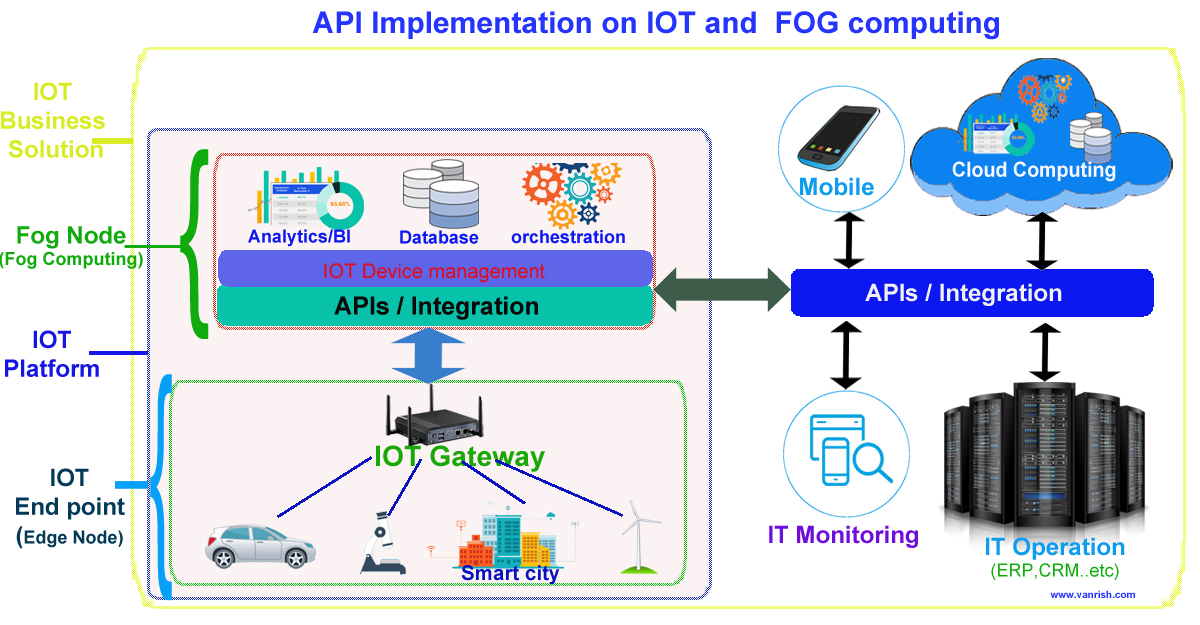
IOT (Internet Of Things) is transforming whole business and bringing new revolution in all kinds of business. These IOT devices generating terabytes of data. To handle unprecedented volume, variety and velocity of data, IOT needs new kind of infrastructure to support whole IOT eco system. FOG computing is a part of IOT eco system to support large volume of data with quick response. I explained in my previous blog, how FOG computing is now becoming major role in IOT devices. FOG is intermediate platform to collaborate between Cloud computing and Edge computing(IOT) to transfer data. Fog can hold small number of data and less computing power. Large data is stored in cloud and heavy computing is done in Cloud.
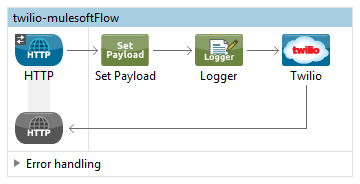
API (Application Programming Interface) have major role to transfer data from edge device (IOT) to Fog node and from fog node to Cloud (Internet). API is helping to collaborate between edge device to Fog node and Fog node to Cloud. API is playing major role to maintain volume, variety and velocity of data in IOT infrastructure.
API works on HTTP/HTTPS protocol. APIs are light weight and simple. Enabling APIs take very small amount of resource. So, API can enable in small system and consume without losing too much resources. This API property helps to transfer data from Edge device(IOT) to Fog node and from Fog node to Cloud. API is not part of mechanical role. API is responsible for the optimization of data transfer. Proper enabling of APIs between these nodes increase the efficiency and computational power to all IOT devices. Fog node is intermediate node between IOT device and cloud. So, Fog node will be responsible to receive data from edge(IOT) device and transfer these data to Cloud. Communication between Edge(IOT) device to Fog node is very frequent. Data provided by API is responsible for all intermediate and quick computation on FOG node.
Cloud is still big stake holder for holding all data and large computation from IOT device. API is providing data to cloud from FOG node in certain interval for heavy computation. As Edge(IOT) system getting more complex Fog computation responsibility will increase and API will come on picture to provide more data to Fog and from fog node to cloud.
These are few benefits by enabling APIs for IOT devices and Fog Nodes
- API provides flexibility to connect any IOT device to FOG node and FOG node to cloud network.
- API provides seamless connectivity between these systems.
- API brings whole IOT system in one seamless environment So, it is very easy to debug these systems.
- API is very easy to develop and deploy so it’s easy to maintain these systems.
- Provisioning of IOT device has also become very easy by enabling API.
- According to Gartner study, Security of IOT is one of big concern. API provides whole one seamless system and network to mitigate this risk.